Availability, Scalability, and Maintainability
First post in my series synopsizing the book Designing Data-Intensive Applications. Today we generalize scaling and maintaining reliable systems.
Welcome to this series, where I'll be condensing down the topics covered in Martin Kleppman's influential book, Designing Data-Intensive Applications

Starting from the early chapters, let's begin by defining Availability, Scalability, and Maintainability.
- If a system is not available, nobody can use it
- If it doesn't scale, then it won't survive success
- If it isn't easy to maintain, then costs (and engineer stress) will skyrocket.
These are the pillars of good system architecture and design. Let's dive deeper into each one.

Availability / Reliability
With concern to software systems, I use availability and reliability them interchangeably. Why? Simple, if a system isn't reliable, then it won't be available when needed.
Don't get me wrong, issues are going to come up in every system. The difference between a highly available system and that car of your brother's that keeps overheating, is that if things go wrong one will keep working while the other will leave you stranded aside the interstate with a burnt hand.
I want to call out the gravity faults carry, as well. They can result in legal issues and damage to your reputation. They may even damage your health or the health of others. Don't take them lightly.
To make this a bit simpler, we can break this down into three categories:
- Hardware Faults
- Software Faults
- Human Errors
Hardware Faults
Hardware faults are not so common for the modern cloud engineer. When I was first serving web apps we deployed on bare-metal servers in a shared data center at a former Air Force base.
When a disk failed or a network card started dropping packets like crazy, we'd have an actual human go out and swap out the failed component with their actual hands. If you can't hot-swap it, you better be sure the load balancer is sending traffic to the other servers before taking the affected server down, or the app goes down with it!

I'm sure this still happens at some level deep within the bowels of the massive GCP, AWS, and Azure mega-datacenters, but my contemporary experience only involves watching a virtual server container die and be automatically replaced within seconds. Pretty abstract.
As nostalgic as that story sounds, it covers all the possibilities you have when encountering a hardware fault:
- Have redundant hardware components
- Have redundant servers (or virtual containers)
Failures can and will happen all the time in the physical world, so make sure that you're prepared to roll over ASAP when needed. When working at the hardware level, this means power backup, RAID disk arrays, multiple Network Interface Cards (NICs), and backup air conditioning units.
These days, in the cloud, be sure to spread your app across availability zones and/or regions. You never know what's gonna happen.
While still studying for my Bachelor's degree, I did system administration and network support for a medical clinic. They had several servers that would mysteriously fail in the middle of the night while running backups. We spent days trying to figure out why the whole rack would reboot, usually within the same half-hour each night.
Turns out the janitor was using an outlet on the same circuit in an adjacent room for his industrial-strength vacuum cleaner. He'd run it until the breaker popped, then he'd flip the breaker back on and go vacuum the next room. We had an electrician remove all outlets outside the server room on those circuits, and the problem disappeared.
Software Faults
Despite our best efforts, we cannot write perfect code every single time. We're also increasing the surface area for issues every time we add another software dependency. There are a few ways we guard against, detect, and recover from software faults:
- Measuring and monitoring. Use telemetry, traces, tools like Real User Monitoring (RUM), and alerting.
- Crashing and restarting. Sometimes the best thing to do is just kill the service and spin up a new one.
- Testing. Unit tests are the table stakes, and you better have this done. You cannot build a house with bricks if some of them are just wet sand. Integration and End-to-end tests will further cover the gaps between components, so don't sleep on those, either.
- Process isolation. This is one of the key ideas behind the Unix/Linux tools like the GNU software. Stick to the single-responsibility principle and you'll reduce the chances of cascading failures across services.
- Checking against guarantees. Coding by contract is something that we do every time we write an API integration. Some languages such as Eiffel include it as a core feature.
Human Errors
I used to work with a skilled Sysadmin who had been around since the early days of networking. He would describe a perfectly reliable system without outages as sitting alone in a climate-controlled room without a keyboard, mouse, ethernet, or wireless communications. "It would run perfectly, almost forever," he'd quip.
Of course, in reality, our systems are useless if nobody and nothing can ever interact with them.
Some of the ways we can allow humans to warm themselves without burning the house down include:
- Minimizing the opportunity for errors. Good UX and HCI guide people towards good actions and away from bad ones. Like door handles that imply whether they should be pushed or pulled, rather than letting you bang the door incorrectly to figure it out.
- Sandboxes. If people must try crazy things, give them a safe sandboxed environment to try them out first. In Scuba diving, for instance, you play around in a pool while learning the equipment, and only head out to open water once you're well trained.
- Testing. Again, the better your tests, the more edge cases and garbage you throw at them, the less likely it is something completely unexpected will occur in production. Don't skimp on these.
A longer tail of things includes creating rollback or "undo" features, monitoring (such as RUM), and training.
People put in bad data, use things in ways we never intended (or imagined!), and take unnecessary risks. We are very good at driving towards our imagined goals despite the tools we've been given, sometimes at the expense of the tool. Let's make sure things still go the right way when that happens.

I do secretly hope that somewhere out there is a perfectly climate-controlled room, empty save for a single server attached to a monitor. The monitor simply displays the output of uptime, which refreshes every second. It's beautiful perfect, and serene.
Scalability
Put simply, scalability is the ability of a system to cope with increased load. What happens when 1000X requests start coming in? What about 1000X the data?
Does it slow down to a crawl?
Start throwing errors?
Crash!?
Not scalable. Bad system. Bad!

Measuring Performance
The most common parameters that can affect the load are:
- Requests per second, or Queries per second (RPS/QPS)
- Data volume
- Read/Write Ratio
- Daily Active Users (DAU)
- Cache hits or misses
How the system performs under load can be measured by:
- Throughput, or how much data the system is handling in a given period (such as Gigabits per second)
- Latency, or the time taken to get and receive a request from a system
- Response time, or how long it takes the system to return a response to a given request, including latency time
Note: some folks use latency and response time interchangeably, or even in the reverse of these definitions - make sure you're aligned!
One thing you might be tempted to do once you start measuring these, however, is to focus on the average or median values. It makes perfect sense, and most of us start here (unless they've read some high-quality blogs like this one first). You can look at these numbers and say, "The average latency for our users is 50ms, with a total response time of 150ms. We're doing great!"
For most queries, you are correct! Good job! The median is a great measure of how the system performs for most requests.
What if 10% of your clients are on the other side of the world, living with 250ms latencies? What if your most important clients, those few power users who are evangelizing your product, have so much data that their requests sometimes take 2-5 seconds?
Storytime:
When I was leading a mobile app team we had great stats that we bandied around a lot. The CEO, however, was not convinced. When he showed us how long it took to take simple actions like loading the home screen, we were mortified.
Because he was dogfooding our services more than anyone else in the world, he had copious amounts of data that required our GraphQL API and PostgreSQL database to do horrific things to serve his instance of the app.
What we did in response was to start using the P95 percentile to measure performance, and focus on improving those response times. With a combination of caching, SQL tuning, and some collaborations with our platform and infrastructure teams, we got our leader back into a healthy place.
Not before I had taken a bunch of heat though!
Percentiles help you measure against the outliers. This is helpful if those indicate either who your most important clients are, or where the greatest issues lie, seething like dragons on their pile of treasure (or in most cases, piles of SQL tables with a lot of joins).
Common percentiles are P50, or the median, P95, which measures the top 5%, and P99, which focuses on the top 1%.

The best thing about using percentiles is that you can then use them to inform your Service Level Indicators (SLIs), Service Level Agreements (SLAs), and Service Level Objectives (SLOs). Management types like me love to say things like "Our SLIs show we are well within the 500ms P95 response time SLA for our clients for the T4W."
Handling the Load
There are primarily three ways to handle an increased load:
- Scale Vertically. This means switching to bigger servers with more CPUs, Memory, Disk Space, or Network Throughput.
- Scale Horizontally. This is where we add more servers to share the workload. Databases and cache servers can be sharded (or partitioned) and stateless application servers can be duplicated and fed traffic through a load balancer.
- Elastic (auto) scaling. This is an extension of horizontal scaling. If we have an array of servers that start getting overwhelmed, a control layer monitors server stats and automatically adds servers as needed, then scales back down once things are calm again. This is a very cost-effective way to deal with spikes in traffic or special circumstances (like a Black Friday sale).
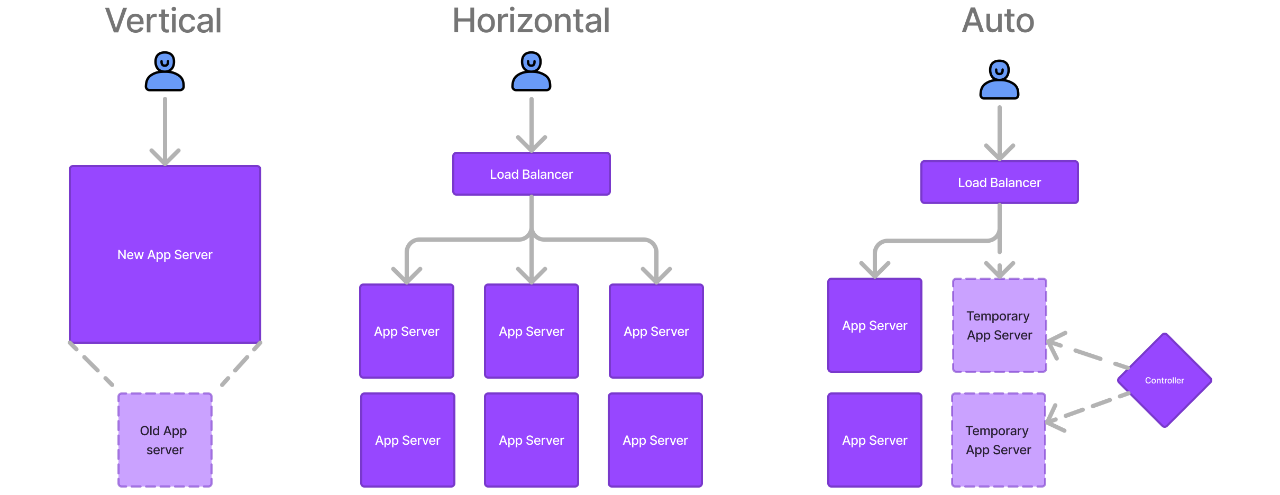
Each choice has drawbacks, though. Vertical scaling has limits; there's a maximum amount of each resource you can fit in a given server. Horizontal scaling seems like a cure-all, but it adds new problems such as race conditions and increased operational and communications overhead. Elastic scaling can even cause more problems if you're experiencing a thundering herd.
Truly an important decision point for your system. Thankfully, if you focus on building maintainable systems and keep tech debt to a minimum, you can always adapt a different scaling pattern when your needs change.
Maintainability
Assuming that we've got Availability and Scalability covered, how do we maintain these systems? Three key ideas are:
- Keep operations easy
- Keep the system simple
- Have a good framework for managing changes
Operations
The daily operations of a modern global-scale system are many.
A non-exhaustive list includes:
- Tracking performance and failures (and doing the post-mortems for the root cause)
- Security and other software updates. These are very important (even for your laptop!)
- Tracking dependencies between services. This will make it easier to know when a service can be deprecated or to inform clients when a service must change
- Anticipating and mitigating issues. The constant battle.
- Tooling and best practices. Hopefully, if you're doing your post-mortems, you're learning how to do better. How are you integrating those learnings?
- Complex maintenance tasks like migrations. Aside from solving real challenges, either legal requirements or a Hacker News hype train will inevitably require migrating one or more of your services. How do you ensure a smooth hand-off?
- Security. Always be alert and stay adaptive.
- Preserving Knowledge. If you win the lottery, will the next person be able to figure out how all this stuff works?
Some things we can do to make operations easier include:
- Monitoring runtime behavior and internals
- Building out supporting automation and common tools
- Building to allow operation when any machine is down
- Documenting behaviors
- Using sane defaults with override abilities
- Building self-healing with manual overrides
- Minimizing surprises
For instance, I was once on a team that supported a fleet of IOT door lock hubs that needed to dynamically program and delete door access codes based on messages from our servers. Unfortunately, some of these messages would get lost or be received out of order. This required maintenance work from us engineers in the form of troubleshooting and parsing logs, and maintenance work from our team on location who had to fix the lock programming manually.
The fix I came up with was to simply have the hubs 'auto-heal' from misconfigurations by regularly sending an idempotent request that included the entire lock programming state. If the hub saw any mismatches with the internal state, it would program the lock to resolve them. This reduced the cost of maintenance for everyone (and made for a better experience for our users, too!).

Simplicity
Abstraction is our best tool for reducing or removing complexity. Consider the example of AWS. There are countless services of varying levels of complexity, but they are all abstracted away by a simple web or CLI interface. Rather than needing to provision a bunch of SAN resources, link them together, and configure an API gateway, a load balancer, and DNS, all I need is a single command:
$ aws s3 mb s3://bucket-name
This prevents a lot of the errors and configuration mismatches that might occur if everything currently handled in the background required manual effort, or even if the S3 interface simply required me to enter the details for all those tertiary resources.
Managing Changes
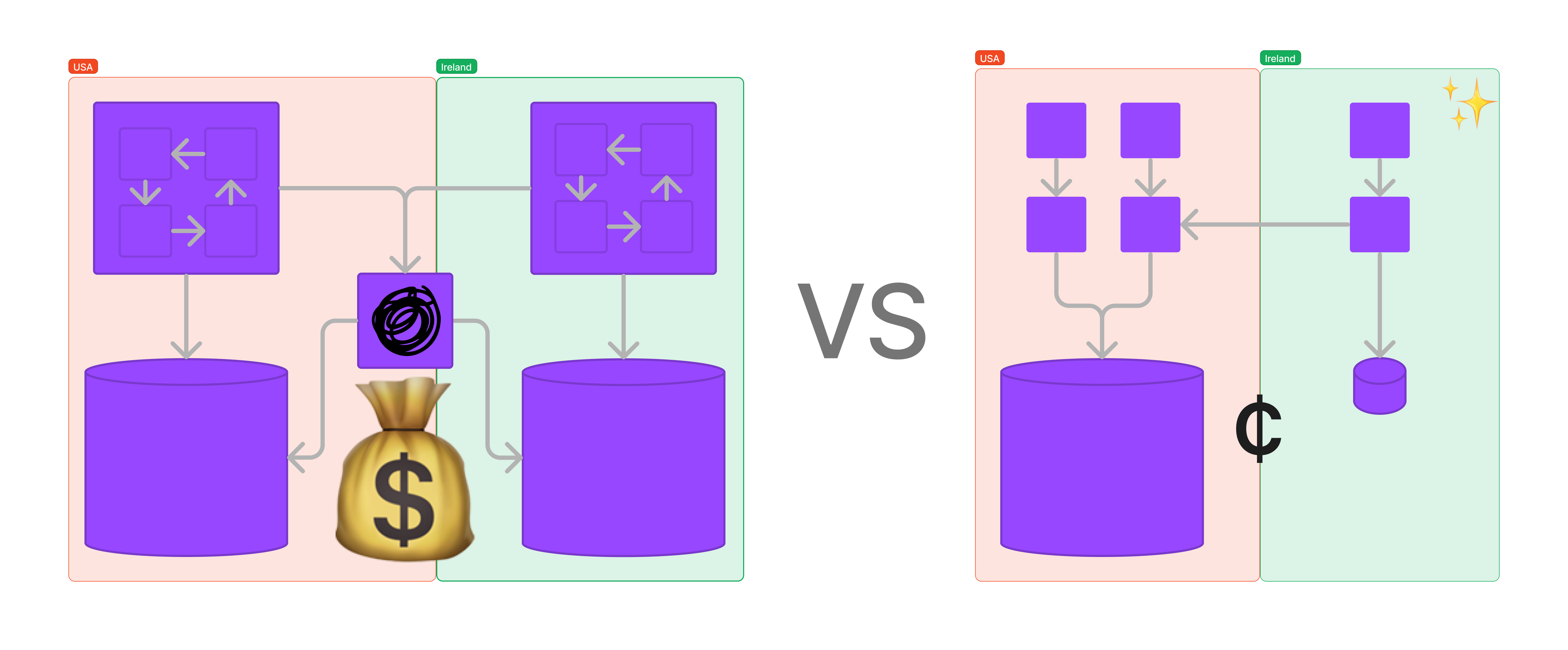
Change is inevitable. Requirements evolve, new features are requested, and the world around our system is constantly in flux. Keep in mind, however, that simpler systems are easier to evolve. Consider the example of a global online ticketing system located in the USA. One day, you're suddenly required to keep the user data related to Irish citizens in Ireland.
If you have a monolithic system with a lot of coupling in the code, and database modules, this is going to be a complex migration. You'll need to create a separate instance of the app server, database, and other components. Then you'll need to set up a temporary ETL to move only the Irish user data, purchases, etc. out to this remote database. Additionally, you'll forever need to keep it in sync with all the ticket and purchase details from the original instance. What a pain!
If, by contrast, your system is more abstracted and simple, where there are discrete services each following the Single Responsibility Principle, then you might have a separate service + datastore for each component. A User service, a User Analytics service, a Ticketing service, and a Purchases service.
You could then easily just store the user data for Irish users from the User service and User Analytics services in new database partitions located in Ireland, and roll out other services slowly as needed. This creates a smaller surface area for problems, and more steps to validate whether things are working or not before fully committing to replicating every piece of the system.
It's also valuable to learn lessons from those who have come before us. Extreme programming and Agile methodologies such as Test-Driven Development and Refactoring were created to handle all the issues that people like us experienced after years of fighting similar battles. These terms have been adopted into the sea of buzzwordy business speak parroted by corporate cogs, almost to the point of being meaningless, but digging in and finding out how to apply those principles and practices in your real work will pay dividends (just not always the kind they're thinking about).
Conclusion
Just to recap, we talked about the three pillars of "Good" software systems:
- Reliability
- Scalability
- Maintainability
If you take nothing else away, just memorize those three words and convert them to questions every time you create or provide feedback on a system architecture:
- How Reliable is this system?
- How Scalable is this system?
- How Maintainable is this system?
I hope you've enjoyed my perspective on this topic. If you did, send me a note: nate@natecornell.com.
If you did not enjoy it, or simply want to correct something I said here, reach out anyways!
This first post in the series was pretty high-level. If you want to go deeper, the next post in this series will dig into data storage and indexing strategies, so look out for it.