The Cache Storage Layer
If your cache is shrinking your cash quicker than your response times, consider a hybrid approach.
I recently attended P99 Conf hosted by ScyllaDB. There were a lot of amazing talks on performance improvements all the way from massive distributed systems like Netflix down to more efficient linting in Rust.
One strategy that came up twice, however, was a creative approach utilizing EC2 that enabled Grafana to scale their cache storage over 40X while spending less on cloud infrastructure(!?). A similar technique was leveraged by RisingWave to avoid high latency and rate limits from blob storage when retrieving shared state.
In both cases, the counterintuitive solution was actually to cache to disk.
Why cache?
Just as a quick reminder why we cache, let's dig into what is likely the most common pattern you'll see in a system design interview, the 3-tier architecture:
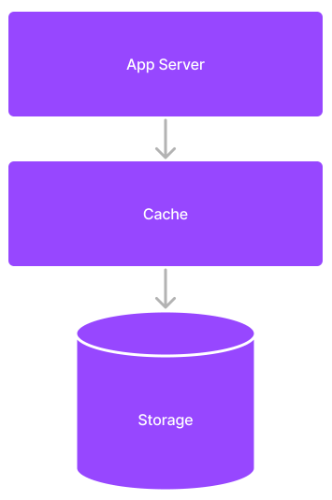
Although it's true that most databases have a pretty good caching system for repeated queries, the rise of complex web applications meant that resolving a single request might take several round-trip database calls. Even if 80% of them are cached, this is still not ideal.
My first introduction to caching was building server-side rendered apps in PHP in the early 2010's. We would hook Apache httpd up to PHP and that to MySQL (the LAMP stack) with Memcached as a pretty simple in-memory key-value pair store. This was great because we could use the app-logic to invalidate a cache, and for things that hadn't changed or been evicted, the performance gains were huge.
Reading 1 MB from random-access memory is about 1 millisecond, but on a spinning disk HDD a random 1MB read is nearly 2 full seconds.[11] That's a 2,000X speedup we were seeing! So of course we started caching everything, everywhere, all at once (or at least according to the Pareto Principle).
What's the cache catch?
Fast forward to the '20s and we're serving massive amounts of data to billions of people all the time.
For instance, if you wanted to start a social media site called "Lie Social" or maybe just "Y" for brevity, and serve 1 Billion daily active users, here's some back of the envelope figures:
- 1 Billion Daily Active Users
- 100,000 Writes per second
- 1 Million Reads per second
- Average post size ~1024 Bytes including metadata
- Cache 1 weeks of posts
- = 100,000 posts * 86400 seconds * 1024 bytes * 7 days
- = 61,931,520,000,000 bytes or ~62 Terabytes of cache 🤯
That's about 500 machines with 128GB of memory each. Looking at AWS at the time of writing, the costs are 67¢ per hour per machine, which comes to $241,200 per month! 💸💸💸
You could hire 12 more Senior engineers at that price. You could have your office lunches catered by a Michelin-star restaurant.
Surely there's a better way!
The Middle Ground
Here's what I synthesized from these two talks:
- Storing some cache data on disk is still pretty fast if it's still close to the requester (as with edge computing)
- Scaling SSDs is way cheaper than scaling DRAM or services like AWS' EBS
Using Memcached extstore caching
In the case of Grafana, they were chunks of log data to objects stores like S3, and found that cache misses were a huge problem. They determined that in order to serve the most requested data efficiently, they would need about 50TB of cache, and faced costs similar to what we predicted for 'Y', in the Michelin lunches range. [2][3]
Because they were already using Memcached, they dug into the docs in search of alternate solutions, and discovered exstore and some success stories implementing it and reducing costs.
At a very high-level, extstore keeps the keys in memory and stores values on the SSD. This greatly reduces the amount of memory needed, and instead puts the pressure on disk size.
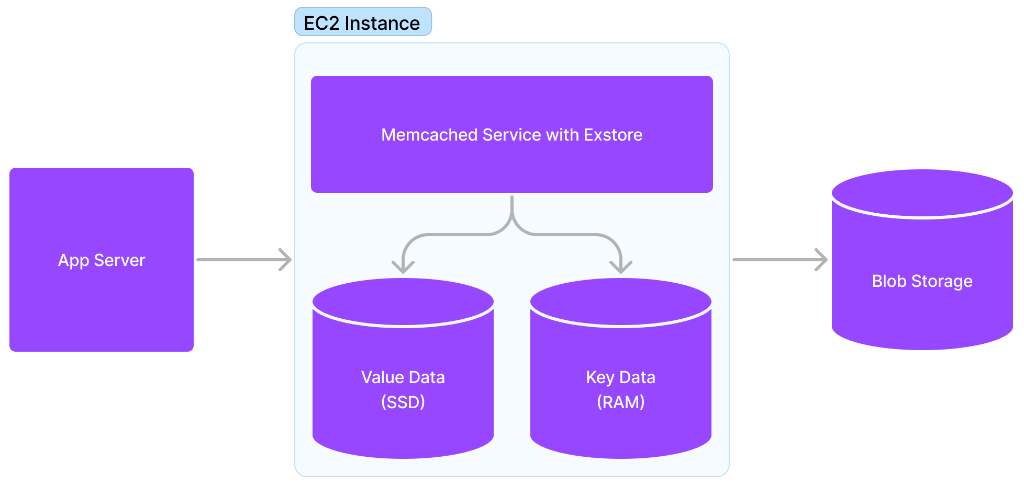
Luckily this is much cheaper. Going back to our 62TB cache example, we could instead have 62 servers each with ~1TB of NVMe storage at 35¢ per hour, or $15,624 per month. That's over 15X cheaper.
Rolling your own state management cache
RisingWave had a very different use case. They support a stream processing service that required shared state storage for the purposes of joining streams. Imagine in an ad network that you need to have session_id available to both your click stream data and your impression stream data and you understand the need.[1]
They were using blob storage for this shared state data, but running into latencies around 100ms. There are also rate limiting issues with S3. A cache was needed, but they skipped in-memory stores.
Instead, RisingWave engineers decided to utilize EC2 storage as a SSD cache solution, and built a very clever LSM-tree model for compacting and storing less recent data in S3. In his P99 talk, Founder Yingjin Wu also mentions considering EBS as a "warm" tier between EC2 and S3, but notes that the cost was prohibitive.
Redis tiered caching
Redis CEO Rowan Trollope has said that they will soon by introducing a flash storage tier for "warm" data. [8]. Without a timeline or any details, we can only hope that it will be as simple as the Memcached exstore solution.
Risks
Beware when using EC2 instances for storage that there is the possibility of data loss. The machines could fault or reboot at any time, so your infrastructure must be able to navigate these occurrences with resilience.
Grafana's solution was to just wipe the disk and rehydrate it.
Conclusion
At the time of this writing, the fastest NVMe drive I can find peaks at 12GB per second[6], and the top DDR4 speed from the same manufacturer is 35GBps[7]. This means that if your in-memory cache hits take 50ms, you might only be looking at 150ms to serve from SSD instead. Still well under the 200ms at which people start noticing a lag.
Combine that with a 15X cost reduction, and it makes sense to consider this tradeoff for your own system architectures.
Please check out the recordings for Danny Kopping's caching talk and Yingjun Wu's state management talk. They're only about 20 minutes each but packed with great content beyond this topic that I barely touched on.
I love learning about how to scale efficiently, so if you have any other thoughts, ideas, or want to correct me on something here, reach out to me at nate@natecornell.com
References
- [1] P99 CONF 2023 | Mitigating the Impact of State Managment by Yingjun Wu
- [2] P99 CONF 2023 | How Grafana Labs Scaled Up Their Memcached 42x & Cut Costs Too by Danny Kopping
- [3] How we scaled Grafana Cloud Logs’ memcached cluster to 50TB and improved reliability
- [4] EC2 On-Demand Pricing
- [5] Extstore In The Cloud
- [6] Crucial T700 1TB PCIe Gen5 NVMe M.2 SSD
- [7] DDR Memory Speeds and Compatibility
- [8] In-memory database Redis wants to dabble in disk - Lindsay Clark
- [9] Exstore
- [10] Extstore In The Cloud - Dormando
- [11] Napkin Math - Simon Eskildsen